We designed FDM-1, a foundation model for computer use. FDM-1 is trained on videos from a portion of our 11-million-hour screen recording dataset, which we labeled using an inverse dynamics model that we trained. Our video encoder can compress almost 2 hours of 30 FPS video in only 1M tokens. FDM-1 is the first model with the long-context training needed to become a coworker for CAD, finance, engineering, and eventually ML research, and it consistently improves with scale. It trains and infers directly on video instead of screenshots and can learn unsupervised from the entirety of the internet.
Before today, the recipe for building a computer use agent was to finetune a vision-language model (VLM) on contractor-annotated screenshots of computer use, then build reinforcement learning environments to learn each specific downstream task. Agents trained this way are unable to act on more than a few seconds of context, process high-framerate video, do long-horizon tasks, or scale to competent agents.
Moreover, training these VLMs requires contractor-labeled annotations. These are expensive, so current computer action datasets are tiny: the largest open dataset is less than 20 hours of 30 FPS video. Meanwhile, millions of hours of film editing, coding livestreams, video game playthroughs, and more have accumulated on the internet over the past two decades. Building a general computer agent requires an internet-scale video corpus, just as building GPT-3 required an internet-scale text corpus. FDM-1 is the first model that can train at this scale.
Here are some demos of our model doing CAD, driving a car, and fuzzing a website!
To train on all this video, you need to label it with actions like key presses and mouse movements. Prior literature has explored automatically labeling data: in Behavior Cloning from Observation, the researchers taught an “inverse dynamics model” (IDM) to label what action was taken between before states and after states in various simulated environments. IDM-labeling is possible for computer use datasets because mouse movement and typing actions are often easily inferable from the screen: if a “K” shows up, you can be reasonably confident the “K” key was pressed. [1] 1. There are harder examples (e.g. a Cmd+V from an earlier Cmd+C) but looking at minutes of history lets us accurately label long-range inverse dynamics, so we can have high confidence in the sequence of actions that produced a given computer state for almost any video. OpenAI’s Video PreTraining (VPT) paper was the first to apply this method at scale, bootstrapping a Minecraft-specific IDM on a small amount of contractor data to create a competent Minecraft agent with six seconds of context. [2] 2. VideoAgentTrek also trained a computer action IDM to label data. The key problem here is they don’t have video context (cannot do Blender or any continuous tasks) and instead rely on screenshot-action-CoT triplets.
VPT’s architecture was able to learn complex behaviors, something still inaccessible to VLM-based approaches. Unlike VPT, however, complex design, finance, and general computer use require not just six seconds, but minutes to hours of context.
The missing piece is a video encoder. VLMs burn a million tokens to understand just one minute of 30 FPS computer data. Our video encoder encodes nearly 2 hours of video in the same number of tokens—that’s 50x more token-efficient than the previous state-of-the-art and 100x more token-efficient than OpenAI’s encoder. These improvements in context length and dataset size mean we can finally pretrain on enough video to scale computer action models.
Training Recipe
Our training recipe consists of three stages (see Figure ?). First, we train an IDM on 40,000 hours of contractor-labeled screen recordings. Second, we use the IDM to label our 11-million-hour video corpus. Finally, we use the IDM-labeled videos to autoregressively train a “forward dynamics model” (FDM) on next action prediction. The FDM’s output token space consists of key presses and mouse movement deltas, expressive enough to model any action taken on a computer.
Video Encoder
Videos of the real world and bodies of text both have relatively uniform information densities throughout, and both can be compressed into a latent representation without losing much semantic content. [3] 3. Generative video models don’t need to see every detail of text on the screen, so they can compress to a very high degree without worrying nearly as much about losing information. Screen recordings are different because information density can vary rapidly. There is a massive information difference between moving a cursor across a blank screen and scrolling through pages of dense text. Existing approaches with fixed-size embedding spaces inevitably trade off between semantic detail and compression ratio.

We created a model without this tradeoff by training our video encoder on a masked compression objective. [4] 4. The V-JEPA paper is similar, but not exactly what we used to enrich our video frame embeddings. We used the core thesis of having a self-supervised prediction task to create expressive embeddings. This unsupervised training enables our encoder to produce information-dense features at a high compression rate. Because our training is unsupervised, we use tasks like inverse dynamics, action prediction, frame reconstruction, and random text transcription to measure the abilities of our encoder.
Comparing our video encoder to a ViT, we observe ~100x faster convergence during training (Figure ?).
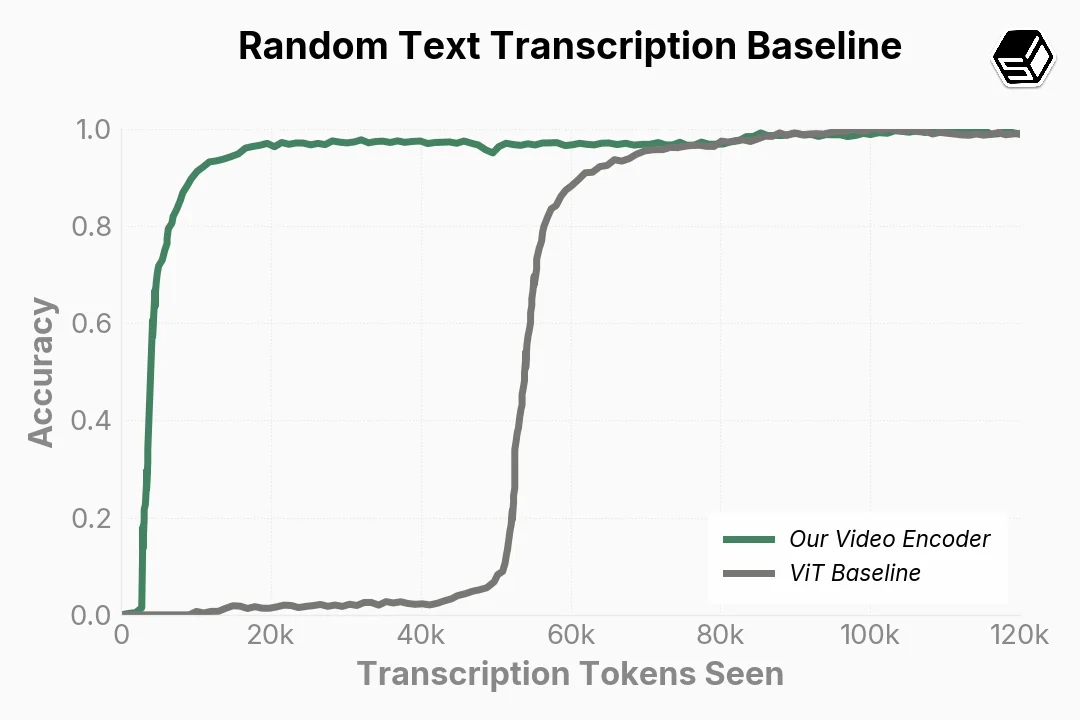
Our encoder achieves a state-of-the-art compression ratio of video frames to tokens, as shown in Figure ?. Our video context unlocks long-horizon workflows such as CAD, while still maintaining the ability to read text with high fidelity.
| Context Window | Average Video Duration |
|---|---|
| 32k tokens | 3 minutes 30 seconds |
| 200k tokens | 20 minutes |
| 1M tokens | 1 hour 40 minutes |
Inverse Dynamics
In order to train on orders of magnitude more labeled data than contractors can provide, we need to automatically label our internet-scale dataset with predicted computer actions—mouse movements, key presses, etcetera. We created an IDM to predict high-quality labels, letting us achieve similar efficiency when training on arbitrary videos as when training on human-gathered ground-truth data.
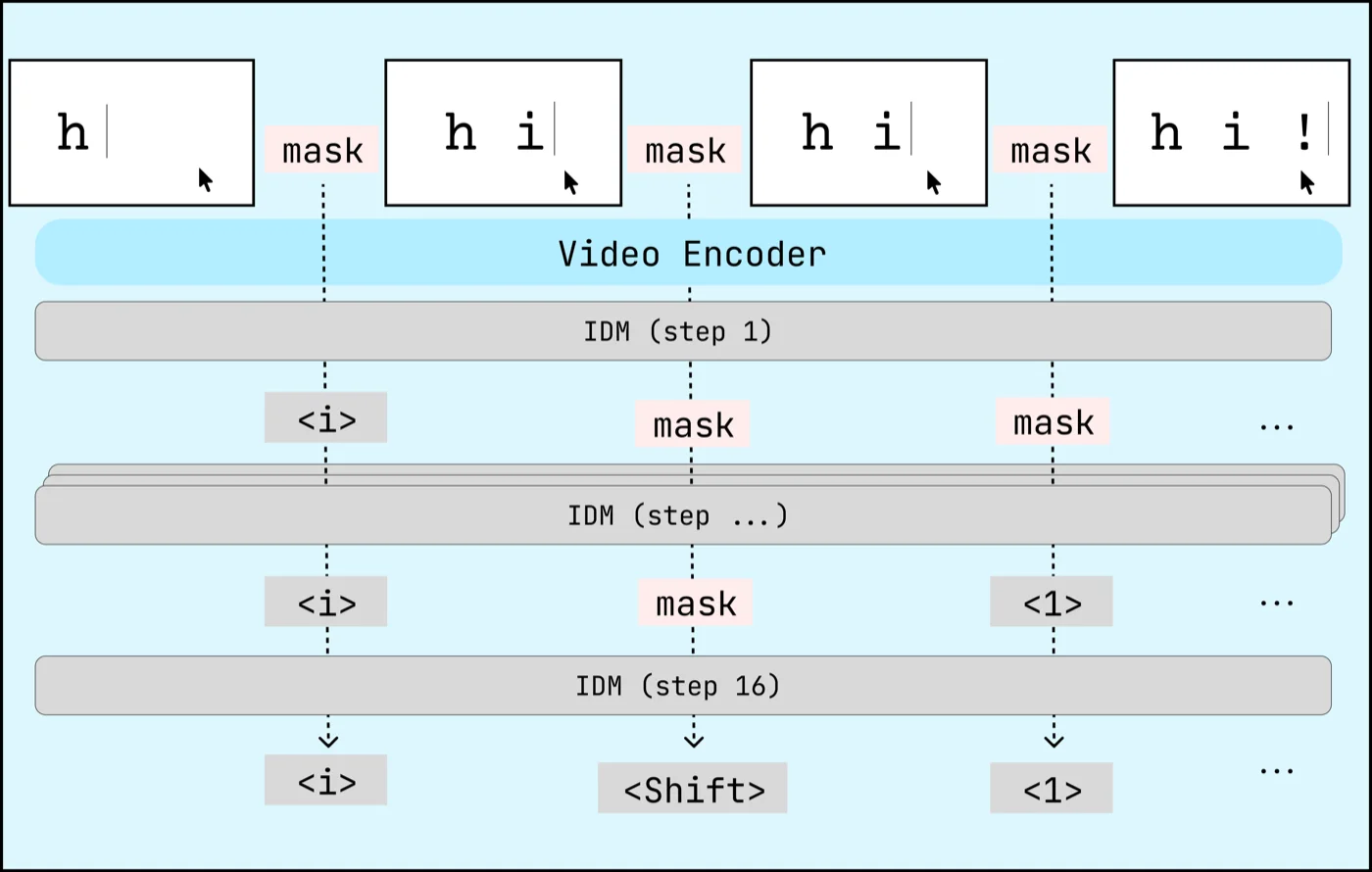
Labeling video is fundamentally non-causal—you can’t label a Cmd+C until you see the resulting pasted sequence. [6] 6. After experimenting with CTC loss as well as normal cross entropy for inverse dynamics modeling, a masked diffusion model performed best. To train a non-causal, generative model, we adopted a masked diffusion architecture. [7] 7. Generative modeling is important to scaffold the action space correctly. When using a non-causal cross-entropy metric, typos were extremely common.
Our masked diffusion method predicts actions conditioned on all frames simultaneously with masked action tokens. During inference, we feed frames interleaved with mask tokens and have the model predict log probabilities for each masked position. We then select the top-k highest-confidence predictions, unmask those tokens, and repeat until the full sequence is labeled.
This way, we can engineer the model to spend baseline effort on high probability actions (by labeling them first) and more effort on ambiguous ones, leading to more accurate labels. This non-causal approach was also more data efficient, overfitting significantly more slowly than causal models. In later sections we show that our IDM achieves near parity with ground-truth contractor data.
Forward Dynamics
The FDM predicts the next action given the prior frames and actions (Figure ?). [8] 8. Labeled data isn’t strictly necessary for prediction because of the near-determinism of computer environments. We exploit this for small-scale experiments, masking action events to slow overfitting. Unlike VLM-based approaches, our FDM operates directly on video and action tokens—no chain-of-thought reasoning, byte-pair encoding, or tool use. [9] 9. We still have transcription tokens during training, mainly for instruction tuning downstream and general language grounding. This is still extremely different from chain-of-thought data because most actions do not have a transcript preceding them. Overall we have ~1.25T transcript tokens This keeps inference low-latency and allows modeling a multitude of tasks that current designs cannot capture—e.g. scrolling, 3D modelling, gameplay. We trained FDM-1 with no language model transfer.
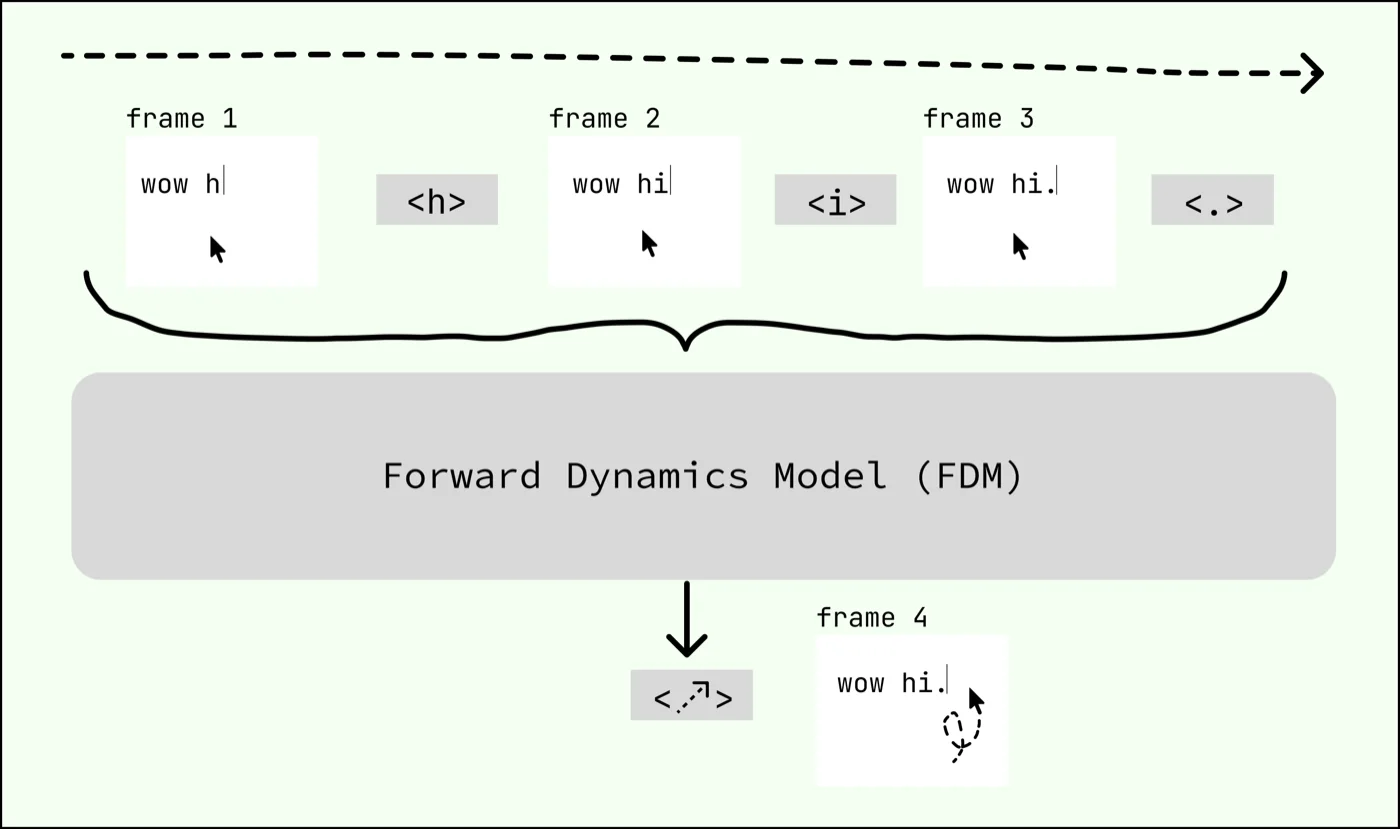
To comprehensively model computer action, we need to tokenize key presses, mouse movements, and scroll events into discrete bins. Key presses and scrolls are easy: we tokenize each key press, key release, and scroll event individually.
Mouse movements are harder to tokenize because the mouse can move any number of pixels per frame—this state space is too large and inefficient to effectively train on. To reduce the state space and use tokens more uniformly, we exponentially bin (Figure ?) the mouse movements. The mouse delta per frame is split into X and Y components. Then, each component is normalized relative to the screen’s width and height before being placed into one of 49 exponentially-sized bins.
This way, small, frequent movements are tokenized into finer bins and large, infrequent movements into coarser ones. We also train our FDM to predict the next click position alongside every mouse movement token, which helps produce accurate trajectories.
Eval Infrastructure
Evaluating an action model requires testing it many times in many live environments. We built eval infrastructure that drives over 1M rollouts per hour across 80,000 forking virtual machines. Each VM is a minimal Ubuntu desktop environment with 1 vCPU and 8GB of RAM; a single H100 can control 42 of these in parallel.
Forking lets us capture a full memory snapshot of an OS state and replicate it onto a fresh VM without corrupting the base environment. This allows us to reuse a single evaluation starting state across thousands of rollouts, effectively leveraging test-time-compute.
Our VM infrastructure is also optimized for low latency. This is important so the model is in distribution during inference because it wasn’t exposed to latency during training—the model has never seen lag before. We mitigate latency through a variety of methods: colocating the GPUs and VMs in the same cloud region, using cumulative sequence length packing, tuning a low-latency VNC configuration, and writing custom Rust bindings for device input. The combination of these optimizations lets us achieve a round trip screen capture to action latency of 11ms.
We use this infrastructure to sample trends on our internal eval suite when comparing training recipes (Figure ?). Here we compare ground-truth contractor data with IDM-labeled data to both determine the quality of the IDM dataset and characterize scaling trends when increasing run sizes.
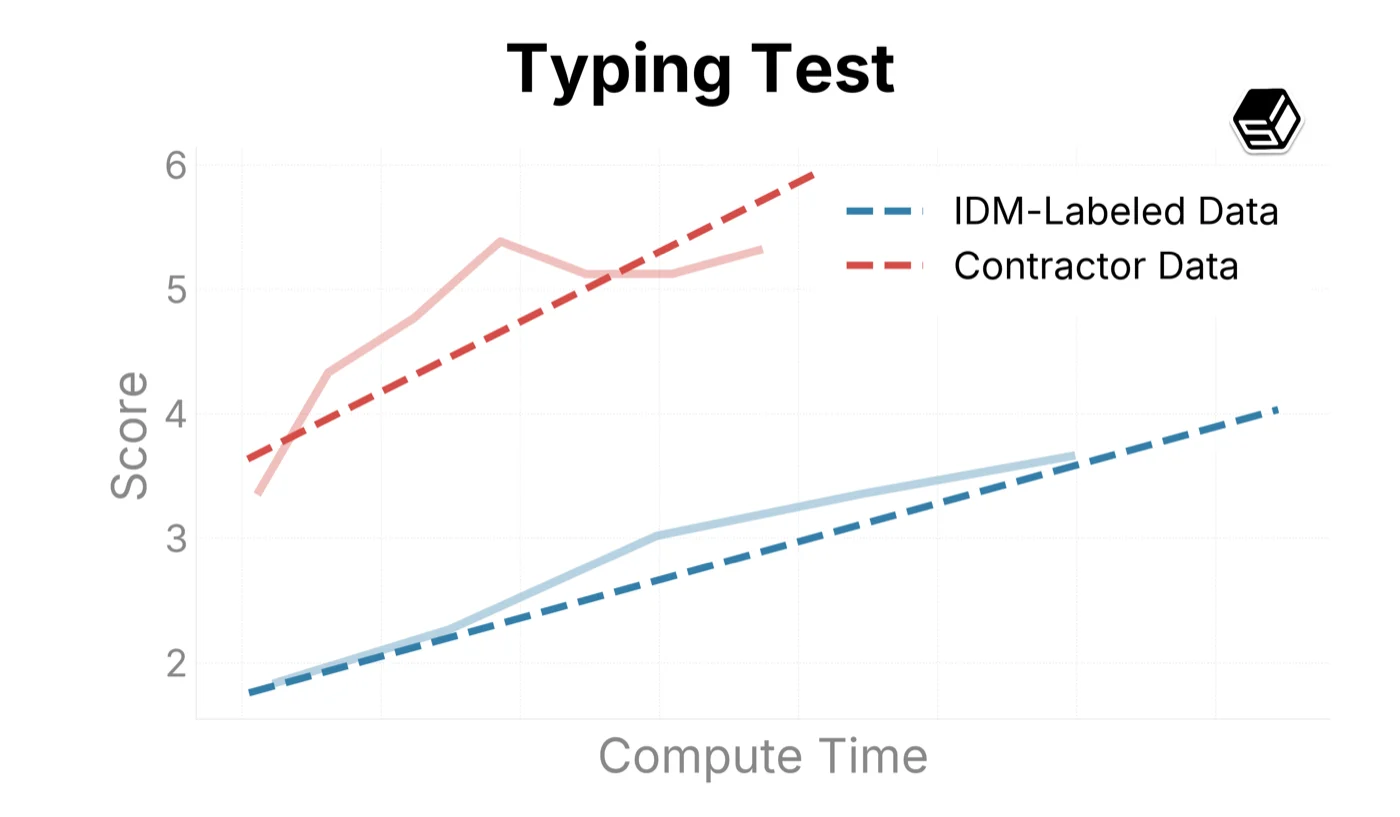
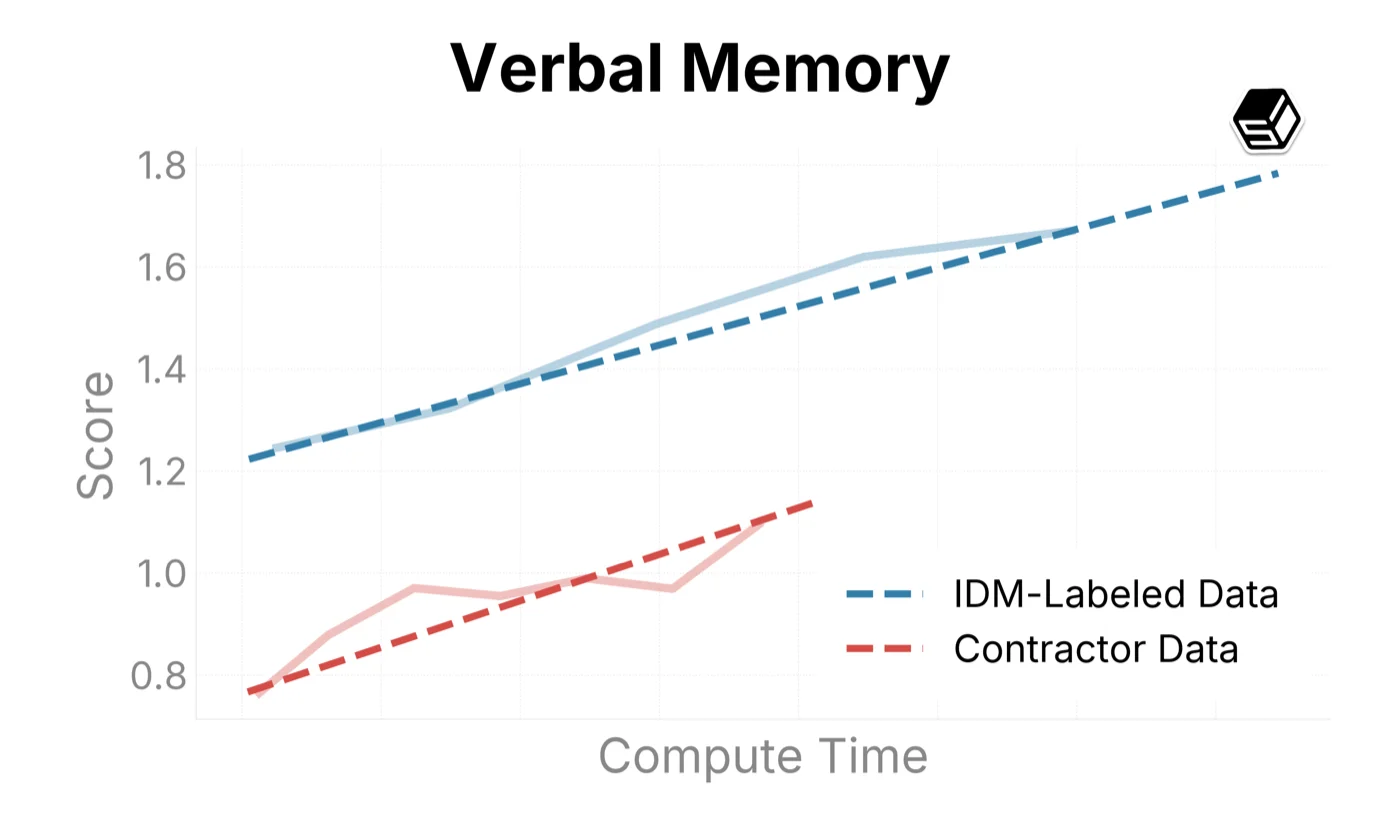
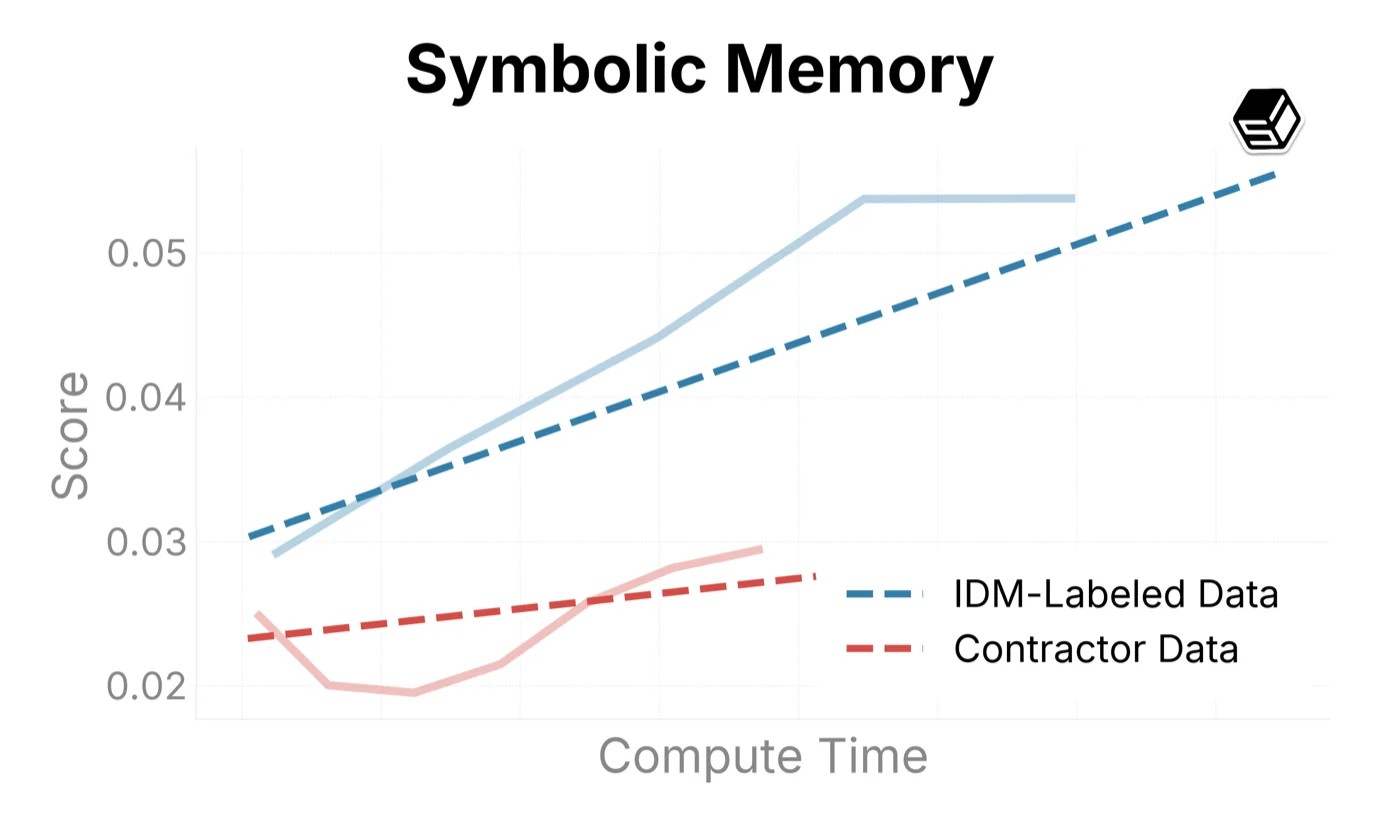
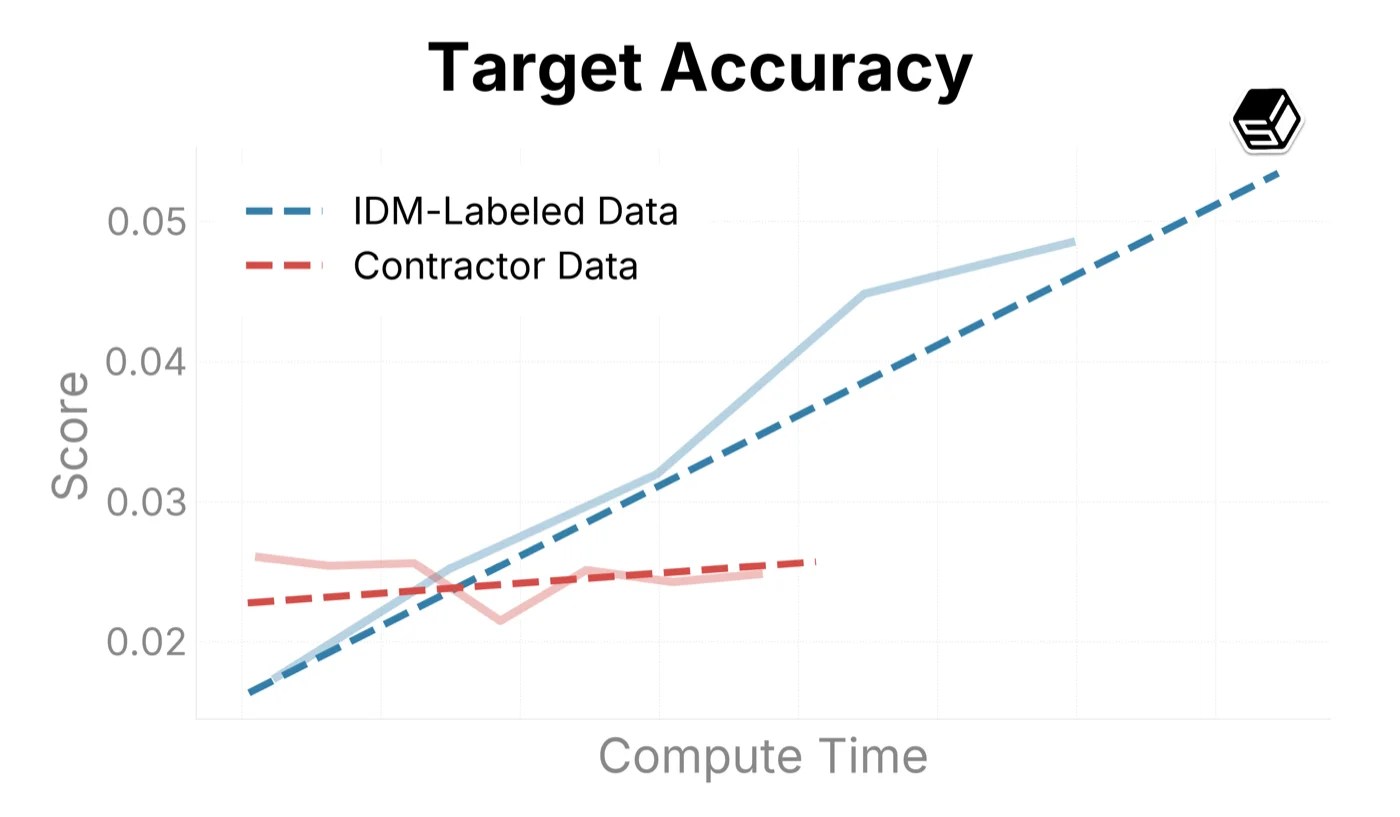
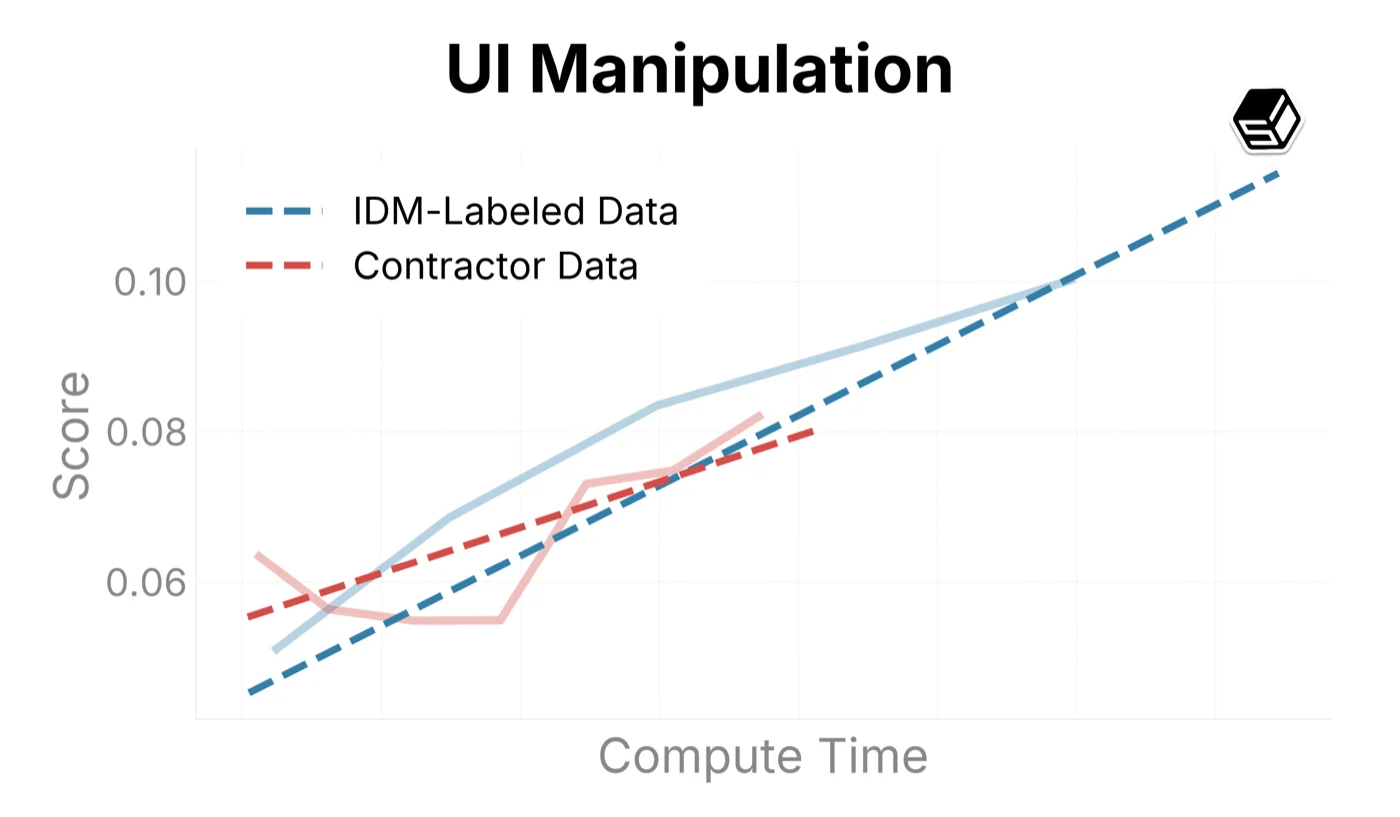
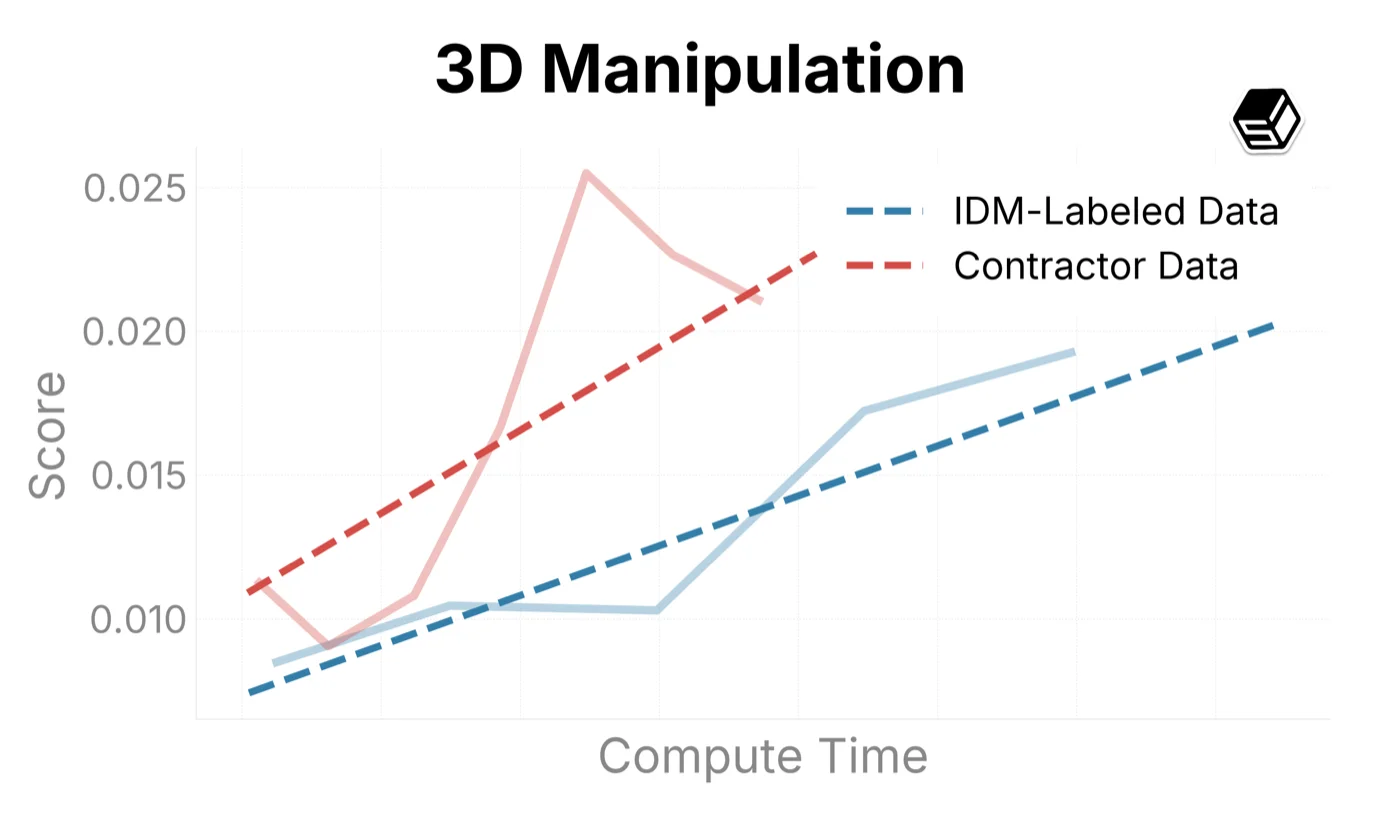
The IDM-labeled data outperforms our contractor dataset in general mouse movement and action capabilities (as seen in Target Accuracy, Symbolic Memory, and UI Manipulation above). For typing and verbal understanding, the model improves on the IDM-labeled data, but more slowly than on contractor datasets. We believe this is caused by noise introduced by the IDM. In the future, we will consider using a mix of IDM and contractor data when scaling up the model.
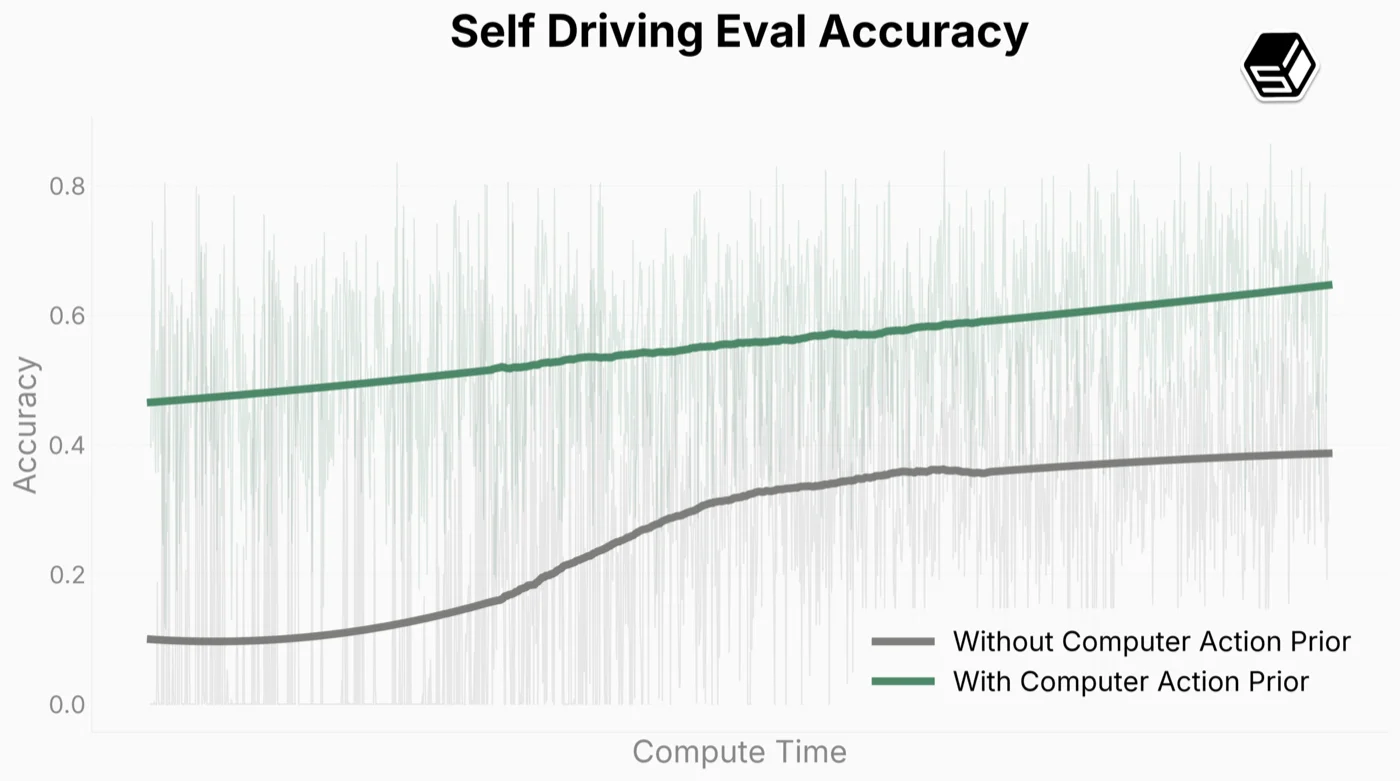
Our model successfully and scalably infers human behavior on complex tasks like object segmentation and 3D manipulation. We also demonstrate that training on computer use generalizes to the real world significantly more easily than a model without such training. In our self-driving tests, the model is able to use a web interface to navigate turns around a block in San Francisco after finetuning on less than 1 hour of collected data. FDM-1 starts with 50% accuracy on key press prediction (a choice between no action, move left, or move right Figure ?), significantly higher than the baseline model with only our video encoder (and no internet video pretraining). Our model also achieves steeper scaling trends compared to the baseline. We expect to achieve zero shot performance on such tasks in the future.
Now What?
Computer action used to be fundamentally data-constrained, expensive, and unscalable. We unlocked both multi-hour 30 FPS video contexts and the ability to train on 11 million hours of data. This brings computer action from a data-constrained regime to a compute-constrained one.
We believe artificial general intelligence will be created within our lifetimes, and likely within the next decade. Our recent work closes the gap on self-directing, competent computer use agents, but there are still a lot of technical problems to be solved before aligned general learners can exist. Standard Intelligence exists to solve these problems.
We’re a small team based in San Francisco. If you’re excited about our work, we’d love to hear from you at [email protected].
Research Team
Thanks to Mohit Agarwal, Carlo Agostinelli, Robert Avery, Cheru Berhanu, Nicholas Charette, Trevor Chow, Luke Drago, Ryan Kaufman, Rudolf Laine, Jinglin Li, Lexi Mattick, Ulisse Mini, Rio Popper, Jannik Schilling, Armando Shashoua, Aidan Smith, Koko Xsu, and Sally Zhu.